
Database tables contain their information in organized records called indexes and use the indexes to store, locate and retrieve data. The two types of indexes being discussed are clustered and non-clustered indexes.
Clustered indexes may also be a primary key for the table, hold all the data for a given table and define the order in which the data records are stored. Additionally, there can only be a single clustered index for any table (and tables without a clustered index are called heaps).
The definition for the clustered index on Erp.JobOper looks similar to the following image.

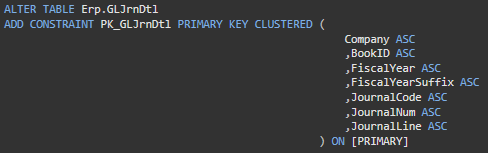
The definition for the clustered index on Erp.GLJrnDtl, where the clustered index is also the primary key, looks similar to the following image.
Non-clustered indexes only contain a portion of a data table's data and are a way to quickly access information based on a different set of criteria (columns) than those defined in the clustered index. There can be multiple non-clustered indexes on any given table, but a word of caution is due, as each non-clustered index consumes space and must also be updated any time a contained column is modified.
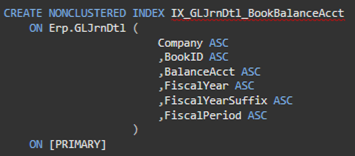
The definition for the non-clustered index 'IX_GLJrnDtl_BookBalanceAcct' on Erp.GLJrnDtl looks similar to the following image.
An important variation of non-clustered indexes is the ability to include additional columns, which allows SQL to both find the data based on a specific set of criteria columns defined on the index, as well as pull additional data from the 'included' columns. This is commonly referred to as a 'covering' index when it covers the need to both find and retrieve data and doing so prevents additional SQL lookups in the clustered index.
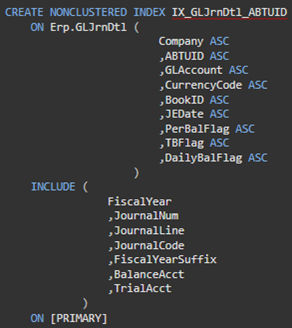
The definition for the non-clustered index 'IX_GLJrnDtl_ABTUID' on Erp.GLJrnDtl looks similar to the following image. Note the 'included' columns section.
Why this is interesting/important
Proper index usage is one important practice that will decrease the wait time for record retrieval and reduce the resource utilization on the database server. Wait time is quite apparent and sometimes accepted as a fact of a complex or large query, but it doesn't always have to be the case. Resource utilization is less apparent but has a broader impact on an environment, and its importance cannot be stressed enough. It affects the environment's scalability, reliability, peak throughput, database contention, potential for deadlocks, and failed transactions, which then leads to a loss of productivity, wasted time to troubleshoot issues and it can even drive a higher SQL licensing cost when additional CPU cores are allocated in SQL to cover less than ideal coding practices.
Consider the following examples, where two sets of queries return the same amount of data but have different performance metrics. Also consider the difference when executed against the tiny Demo Database (10.2.700.x) with 4.59 gigabytes of utilized space versus a more normal production database (10.2.400.x) utilizing 181.49 gigabytes of space. This demonstrates what many companies find out the hard way - less than ideal coding practices work fine on a small database (IE, as companies start out with Epicor), but don't scale well, utilize too many resources and are costly to either correct or leave as-is.
Consider the simple task of joining together the InvcDtl, ShipDtl & OrderRel tables in the following examples, where Company is used in the where clause of the first query of each example (allowing the use of the table indexes) and Company is missing from the where clause in the second query of each example (forcing SQL to perform a costly table scan). Ordinarily more tables would be joined to make such a result more useful, and fewer fields would likely be returned, but regardless, the examples illustrate the impact of using the indexes vs not using the indexes in queries.
Several notes on the performance testing metrics:
- CPU time = CPU time the query consumed to find and return results.
- Elapsed Time = time it took for the query to execute and return results to the user.
- Query results have the 'Discard results after execution' option selected, so the results strictly a measure of SQL Server's performance and not the client or network performance.
- The first couple sets of results were not recorded, as these often times include performance penalizing activities, such as creating an execution plan and disk IO when the data was initially read into memory.
Demo Database
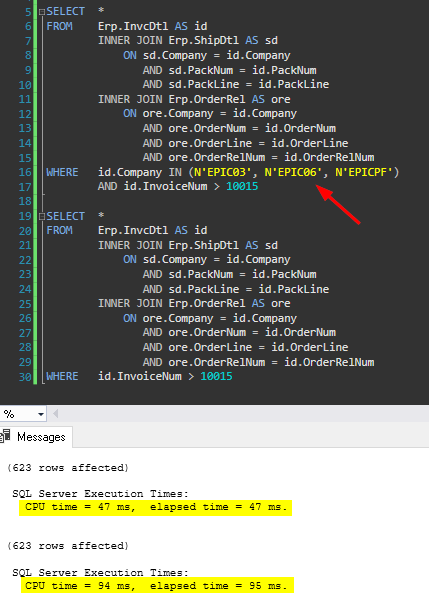
Company is used in all Joins.
First query uses a few specific companies and an InvoiceNum to filter, while the second only uses the InoivceNum.
623 Rows returned for each query.
Result:
Using the company clearly improves the performance, but the database is so small, the difference would be imperceptible without measuring the metrics.
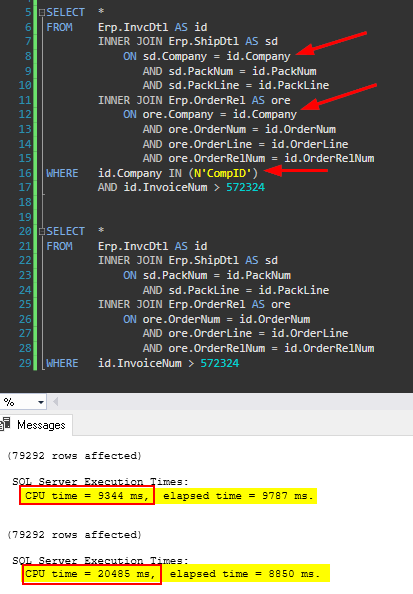
Production Database - Example 1
Company is used in all Joins.
First query uses a one specific company and an InvoiceNum to filter, while the second only uses the InoivceNum.
79,292 Rows returned for each query.
Result:
Again, using the company clearly improves the performance as seen prior, but this time it would be noticeable to a user running the query, as it has about a 3.3 second impact.
Also shown are the logical reads, demonstrating SQL reads about twice as much data from the ShipDtl and about three times as much data from InvcDtl table on the query not using Company in the where clause, when compared to the first query. This would have a much greater impact than 3.3 seconds if the data were not already cached in memory.
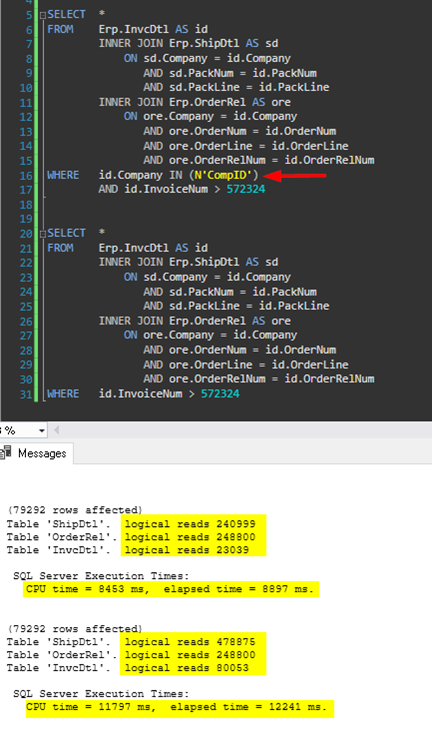
Production Database - Example 2
Company is used in all Joins of first query and not in the joins of the second query.
First query uses one specific company and an InvoiceNum to filter, while the second only uses the InoivceNum.
79,292 Rows returned for each query.
Result:
The first query, which is properly written took 9.7 seconds to return the data, while the second query took less time, at 8.8 seconds. Why is the 'improperly written' query now the fastest?
This demonstrates that the improperly written query is actually utilizing far more resources to return the result, such much so that the SQL engine chose a parallel execution plan for the improper query. This resulted in a faster overall execution time, but consumed more than twice the amount of CPU resources to return the results - 20.4 seconds versus 9.3 seconds. This is another case that would only be found by reviewing the performance metrics or troubleshooting resource issues.
How to Get Started
There are several ways to get started in using indexes, but the easiest with Epicor is to use the 'Company' column in nearly every join or when adding a where clause to filter results. Epicor has logical layouts for most indexes, such as with OrderRel, where the clustered index is by Company, OrderNum, OrderLine and OrderRelNum. Using company consistently in joins will not only help with performance but will also help ensure that code is multi-company safe, which could be relevant now or at a future point for various reasons. It's also important to note that using indexes applies any time data is accessed from the database, which includes such touchpoints as: BAQs, BPMs / DDs, LINQ queries, Reports, SSMS, ODBC, etc.
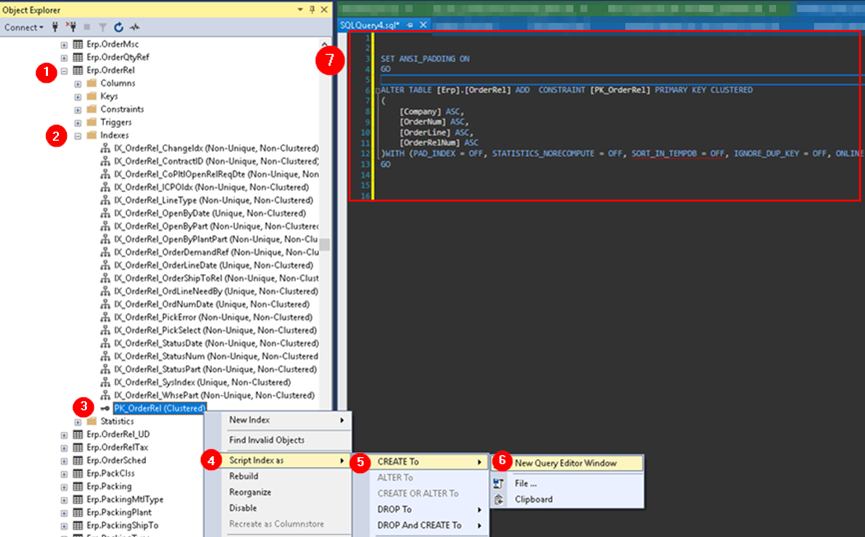
To find the fields included in a specific index, the most direct method involves using SQL's object explorer window to expand the Sever Instance > Database > Table > Indexes area, and then scripting the index to a new query editor window, which allows viewing the index definition. This can be tedious to perform numerous times, though Epicor has done a good job of naming the indexes and a somewhat targeted approach can most often be used.
Object Explorer Window location:
Scripting an index to a new query window (#1 starts at the table within a specific database, #7 shows the results of scripting the index to a new query):
Measuring performance metrics:
The simplest metrics to use (if using SSMS) are the ones shown in the examples above, where the following two statements are executed at the beginning of the script.

SET STATISTICS IO ON will cause the following information to be shown in the 'Messages' tab in SSMS, which provides guidance in data IO for an executed statement.
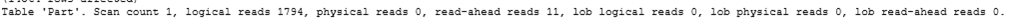
SET STATISTICS TIME ON will cause the following information to be shown in the 'Messages' tab in SSMS, which provides the CPU and Elapsed time for an executed statement.

Epicor's BAQ designer will return basic timing information by default. This will not help identify situations where the CPU time is greater than the elapsed time.
Should all non-optimal queries be rewritten? No, that'd generally be inadvisable. Rewriting queries is not without risk and can be time-consuming in some cases. The best route forward should be a multi-pronged approach:
1. Allocate more CPU as a short term solution (virtual environments only!).
Allocating additional CPU does not address the underlying cause but can be the quickest short-term work-around when poor coding causes CPU contention. This may keep the system operational long enough to address the poorly performing queries.
Be aware that this may increase your SQL licensing costs. Also be aware that over provisioning of CPU resources on a virtual environment's host should never occur for a production SQL environment running an ERP system, such as Epicor, and allocating more CPU in those cases could cause additional CPU contention.
2. Focus on re-writing poorly written queries that have the greatest impact.
For instance, queries that cause users to wait too long for results or cause other processes to fail through record locking, etc.
A query that takes 10 minutes (600 seconds) too long to execute but executes once nightly when users aren't impacted is arguably unimportant compared to a query that takes 250 milliseconds too long, but is called twice for every line loaded on a sales order. That comes from a real-world example, and while 250 milliseconds (1/4 of a second) doesn't sound like much, it quickly adds up when considering it was called twice for ever order line that was loaded. That adds an additional 5 seconds for every load or refresh of a 10 line sales order and 25 additional seconds on a 50 line sales order.
3. Focus on releasing properly written code into production going forward.
For example, ensure your code is making proper use of the database indexes and performs satisfactorily, to not compound what could become a crippling issue during times of peak demand for a business.